CarND-Advanced-Lane-Lines-P4
Udacity Self Driving Car Nanodegree - Advance Lane Line Finder on a Video Stream
Prerequisites
To run this project, you need Miniconda installed(please visit this link for quick installation instructions.)
Installation
To create an environment for this project use the following command:
conda env create -f environment.yml
After the environment is created, it needs to be activated with the command:
source activate carnd-term1
Project
Goals
The goals/steps of this project are the following:
- Compute the camera calibration matrix and distortion coefficients given a set of chessboard images.
- Apply a distortion correction to raw images.
- Use color transforms, gradients, etc., to create a thresholded binary image.
- Apply a perspective transform to rectify binary image (“birds-eye view”).
- Detect lane pixels and fit to find the lane boundary.
- Determine the curvature of the lane and vehicle position on center.
- Warp the detected lane boundaries back onto the original image.
- Output visual display of the lane boundaries and numerical estimation of lane curvature and vehicle position.
Rubric points
Writeup / README
1. Provide a Writeup / README that includes all the rubric points and how you addressed each one. You can submit your writeup as markdown or pdf. Here is a template writeup for this project you can use as a guide and a starting point.
You’re reading it!
Camera calibration
1. Briefly, state how you computed the camera matrix and distortion coefficients. Provide an example of a distortion corrected calibration image.
The camera calibration code could be found on the 01-Camera Calibration notebook. Using cv2.findChessboardCorners, the corners points are stored in an array imgpoints for each calibration image where the chessboard could be found. The object points will always be the same as the known coordinates of the chessboard with zero as ‘z’ coordinate because the chessboard is flat. The object points are stored in an array called objpoints. I then used the output objpoints and imgpoints to compute the camera calibration and distortion coefficients using the cv2.calibrateCamera function. I applied this distortion correction to the test image using the cv2.undistort function and obtained this result:
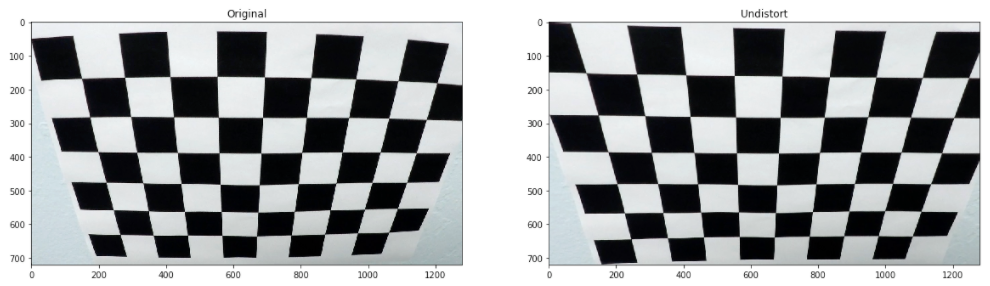
The camera calibration and distortion coefficients are stored using pickle to be used on the main notebook
Pipeline (single images)
The code used to implement these functionality could be found at Advanced Lane Lines notebook.
1. Provide an example of a distortion-corrected image.
The camera calibration calculation was done on the 01-Camera Calibration notebook. The result is load with pickle on In[2].
The following image shows the result of applying the camera calibration to one of the test images:

2. Describe how (and identify where in your code) you used color transforms, gradients or other methods to create a thresholded binary image. Provide an example of a binary image result.
The code used to experiment with color, gradients, and thresholds could be found on the 02-Color Transform and Gradients Threshold notebook.
A color transformation to HLS was done In [6] and the S channel was selected because it shows more contracts on the lane lines as shown in the next figure:

After the color transformation had been done, it was time for gradients. The following gradients were calculated:
- Sobel X and Sobel Y:
In [10]andIn [11] - Magnitude :
In [13] - Gradient direction :
In [14] - Combination of all the above (Sobel X and Sobel Y) or (Magnitude and Gradient):
In [16]
After a few back-and-forward exploration with thresholds, the following picture will show the different gradients on some test images side-by-side:

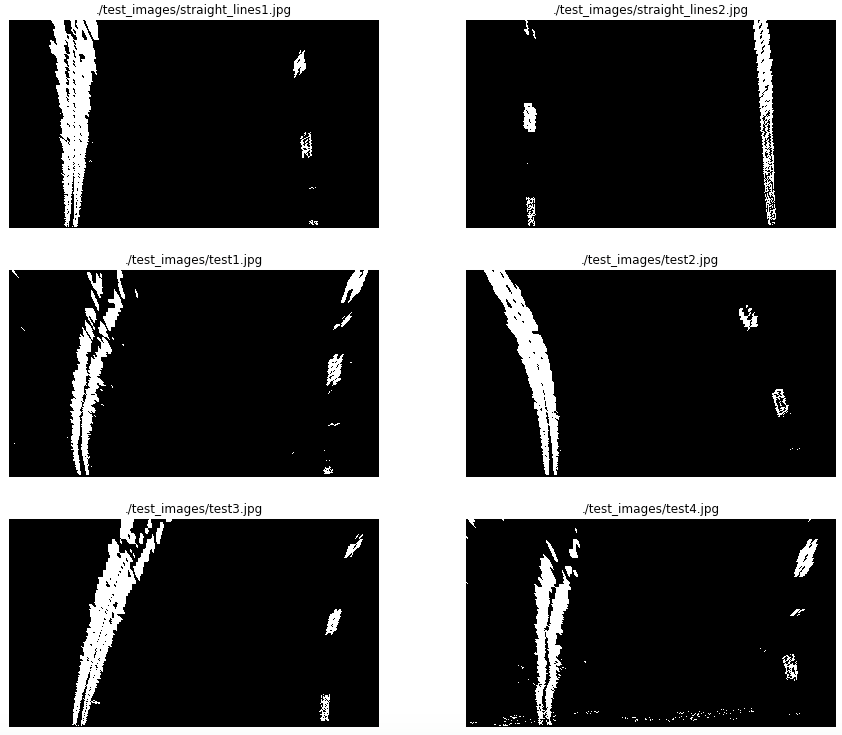
The full combination of these gradients leads to a “noisy” binary image. That is why on the main notebook Advanced Lane Lines notebook. Only the combination of Sobel X and Sobel Y was used to continue with the pipeline. The following image shows the binary image obtained with that combination on the test images:

On the Advanced Lane Lines notebook, the code used to calculate this images is from In [7] to In [13].
3. Describe how (and identify where in your code) you performed a perspective transform and provided an example of a transformed image.
The perspective transformation code could be found on 03-Perspective transformation notebook. The image used were the one with straight lane lines:
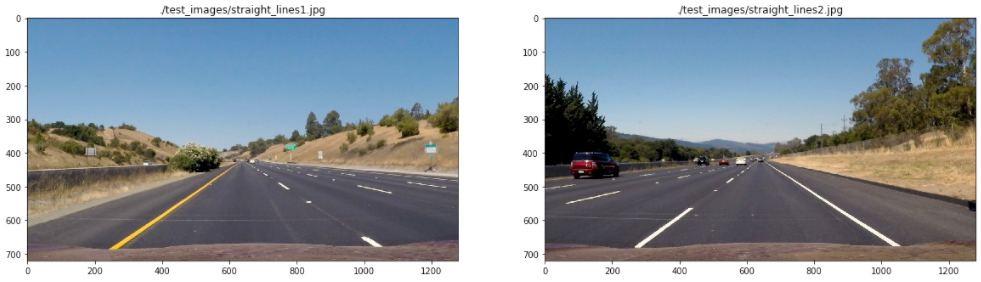
Four points where selected on the first image as the source of the perspective transformation. Those points are highlighted on the following image (In [4]):

The destination points for the transformation where to get a clear picture of the street:
| Source | Destination |
|---|---|
| (585, 455) | (200,0) |
| (705, 455) | (maxX - 200, 0) |
| (1130, 720) | (maxX - 200, maxY) |
| (190, 720) | (200, maxY) |
Using cv2.getPerspectiveTransform, a transformation matrix was calculated, and an inverse transformation matrix was also calculated to map the points back to the original space (In [5]). The result of the transformation on a test image is the following:
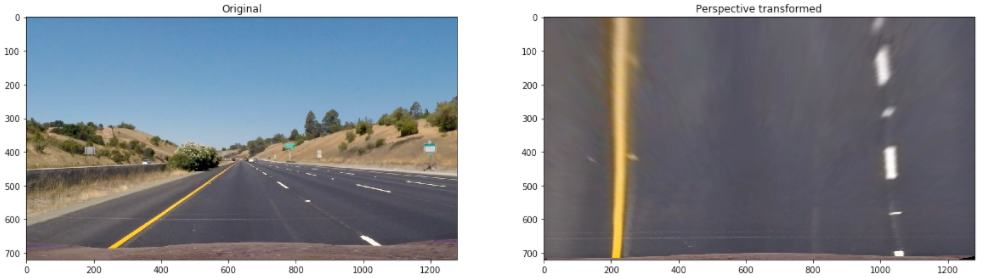
The transformation matrix and the inverse transformation matrix was stored using pickle to be used on the main notebook Advanced Lane Lines notebook. The following picture shows the binary images results after the perspective transformation:
4. Describe how (and identify where in your code) you identified lane-line pixels and fit their positions with a polynomial?
The line detection code could be found at In [17] of the Advanced Lane Lines notebook. The algorithm calculates the histogram on the X axis. Finds the picks on the right and left side of the image, and collect the non-zero points contained on those windows. When all the points are collected, a polynomial fit is used (using np.polyfit) to find the line model. On the same code, another polynomial fit is done on the same points transforming pixels to meters to be used later on the curvature calculation. The following picture shows the points found on each window, the windows and the polynomials:

5. Describe how (and identify where in your code) you calculated the radius of curvature of the lane and the position of the vehicle on the center.
On the step 4 a polynomial was calculated on the meters space to be used here to calculate the curvature. The formula is the following:
((1 + (2*fit[0]*yRange*ym_per_pix + fit[1])**2)**1.5) / np.absolute(2*fit[0])
where fit is the the array containing the polynomial, yRange is the max Y value and ym_per_pix is the meter per pixel value.
To find the vehicle position on the center:
- Calculate the lane center by evaluating the left and right polynomials at the maximum Y and find the middle point.
- Calculate the vehicle center transforming the center of the image from pixels to meters.
- The sign between the distance between the lane center and the vehicle center gives if the vehicle is on to the left or the right.
The code used to calculate this could be found at In [20].
6. Provide an example image of your result plotted back down onto the road such that the lane area is identified clearly.
To display the lane lines on the image, the polynomials where evaluated on a lineal space of the Y coordinates. The generated points where mapped back to the image space using the inverse transformation matrix generated by the perspective transformation. The code used for this operation could be found on In [19], and the following images are examples of this mapping:

Pipeline (video)
1. Provide a link to your final video output. Your pipeline should perform reasonably well on the entire project video (wobbly lines are ok but no catastrophic failures that would cause the car to drive off the road!).
After some refactoring of the code found at In [21], the project video was processed and the results at video_output
Discussion
1. Briefly, discuss any problems/issues you faced in your implementation of this project. Where will your pipeline likely fail? What could you do to make it more robust?
- There are a few improvements that could be done on the performance of the process due to repetitive calculations.
- More information could be use from frame to frame to improve the robustness of the process.
- Other gradients could be use (Ex. Laplacian) to improve the line detection.